A medida que nos adentramos en 2026, el prompt engineering ha trascendido el arte de formular preguntas para convertirse en una disciplina sistemática y crucial para la interacción con la inteligencia artificial. Ya no se trata solo de dar instrucciones, sino de diseñar arquitecturas de comunicación que guíen a los Modelos de Lenguaje Grandes (LLM) hacia razonamientos complejos, mayor fiabilidad y una eficiencia sin precedentes. Esta guía explora las técnicas más evolucionadas y efectivas, con un enfoque en su aplicación práctica.
1. La evolución del razonamiento estructurado: de cadenas a grafos
La capacidad de los LLM para resolver problemas complejos ha mejorado drásticamente gracias a técnicas que imitan y estructuran el proceso de pensamiento humano. Esta evolución representa el pilar del prompt engineering avanzado.
Chain of Thought (CoT): El Fundamento del razonamiento
La técnica de Cadena de Pensamiento (CoT) fue un punto de inflexión, instruyendo a los modelos a «pensar en voz alta» y descomponer un problema en pasos intermedios antes de dar una respuesta final. En lugar de saltar a una conclusión, el modelo genera una secuencia lógica de razonamiento.
Su eficacia está ampliamente documentada. Por ejemplo, en el benchmark MMLU-Pro, la precisión de GPT-4o mejora en 19.1 puntos porcentuales (de 53.5% a 72.6%) simplemente añadiendo la instrucción «Piensa paso a paso» . Este método es especialmente útil para problemas matemáticos, lógicos y de planificación.
Ejemplo de prompt CoT: Pregunta: Si un tren viaja 30 millas en 50 minutos, ¿qué distancia recorrerá en 1.5 horas (90 minutos) a la misma velocidad? Piensa paso a paso antes de generar la respuesta final y muestra todos los pasos intermedios.
Tree of Thoughts (ToT): Exploración de múltiples caminos
El Árbol de Pensamientos (ToT) generaliza el CoT al permitir que el modelo explore múltiples ramas de razonamiento simultáneamente. En cada paso, el LLM genera varias ideas o «pensamientos«, los evalúa y decide qué camino es más prometedor, pudiendo incluso volver atrás si una vía parece incorrecta. Este enfoque, inspirado en la resolución de problemas humanos mediante ensayo y error, es significativamente más robusto para tareas que requieren exploración o una visión estratégica .
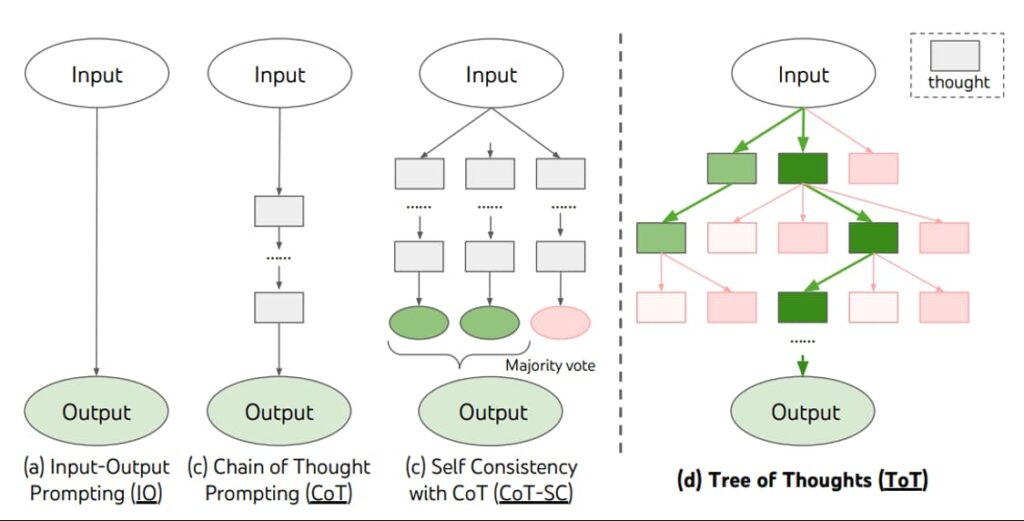
Ilustración del framework ToT, donde el modelo explora y evalúa múltiples ramas de pensamiento. Fuente: Yao et al. (2023).
La superioridad de ToT ha sido demostrada en benchmarks complejos. En el «Juego del 24«, donde se deben combinar cuatro números para obtener 24, GPT-4 con CoT solo resolvió el 4% de los casos, mientras que con ToT alcanzó una tasa de éxito del 74% . Esto evidencia un salto cualitativo en la capacidad de razonamiento del modelo.
Ejemplo de prompt ToT (adaptado de Vellum.ai):Imagina que tres expertos diferentes están respondiendo a esta pregunta.
Todos los expertos escribirán 1 paso de su pensamiento y luego lo compartirán con el grupo.
Luego, todos los expertos pasarán al siguiente paso, y así sucesivamente.
Si algún experto se da cuenta de que está equivocado en algún momento, se retira.
La pregunta es…
Graph of Thoughts (GoT): La frontera del razonamiento conectado
El Grafo de Pensamientos (GoT) es la evolución más reciente y flexible, superando las limitaciones de las estructuras lineales (CoT) y de árbol (ToT). GoT modela los pensamientos como nodos en un grafo, permitiendo no solo la ramificación, sino también la fusión de diferentes líneas de pensamiento . Esto posibilita la combinación de soluciones parciales, la creación de ciclos de retroalimentación para refinar ideas y la modelización de procesos de pensamiento no lineales, más parecidos a la cognición humana.
Los resultados son contundentes: en tareas de clasificación, GoT ha demostrado mejorar la calidad en un 62% en comparación con ToT, al tiempo que reduce los costos en más de un 31%. Esta eficiencia se logra al permitir que el modelo agregue y sintetice información de múltiples ramas de razonamiento en un nuevo pensamiento unificado.
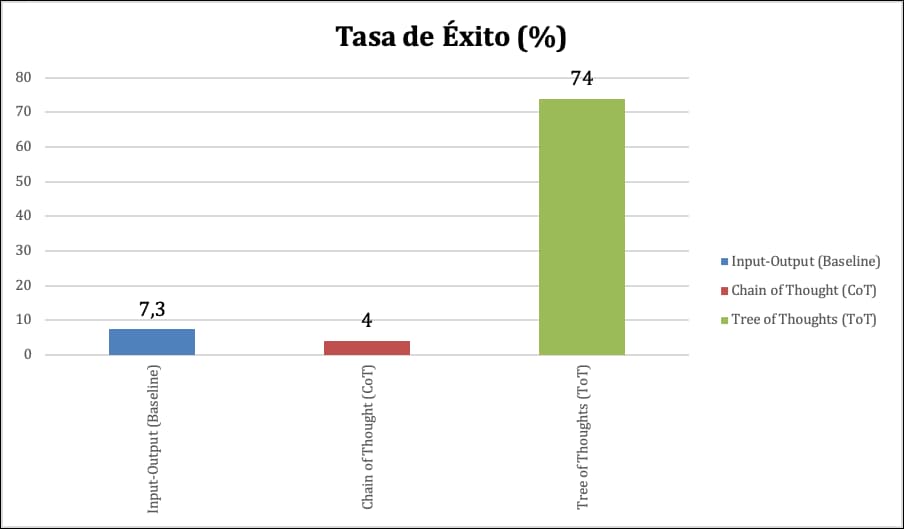
Comparación de la eficacia de las técnicas de razonamiento en el «Juego del 24». Datos de Zero To Mastery.
2. Técnicas de optimización y fiabilidad
Más allá de la estructura del razonamiento, existen técnicas avanzadas diseñadas para mejorar atributos específicos de las respuestas del LLM, como la veracidad, la velocidad y la relevancia.
Chain of Verification (CoVe): Combatiendo las alucinaciones
Uno de los mayores desafíos de los LLM son las «alucinaciones» o la generación de información plausible pero factualmente incorrecta. La Cadena de Verificación (CoVe) aborda este problema mediante un proceso de autocrítica estructurado .
El proceso consta de cuatro pasos clave:
- Generar una respuesta base: El modelo produce un borrador inicial.
- Planificar la verificación: El modelo genera una lista de preguntas para verificar los hechos de su propio borrador.
- Ejecutar la verificación: El modelo responde a cada pregunta de forma independiente para evitar sesgos.
- Generar la respuesta final verificada: Se genera una respuesta final y refinada, incorporando los resultados de la verificación.
Esta técnica ha demostrado reducir significativamente las alucinaciones. En tareas de preguntas y respuestas de libro cerrado (closed-book QA), CoVe mejoró la puntuación F1 en un 23% . Es una herramienta indispensable para aplicaciones donde la precisión factual es crítica.
Skeleton of Thought (SoT): Acelerando la generación de respuestas
La latencia puede ser un problema en aplicaciones en tiempo real. El Esqueleto de Pensamientos (SoT), propuesto por investigadores de Microsoft y la Universidad de Tsinghua, aborda este desafío imitando cómo los humanos estructuran sus ideas: primero un esquema, luego los detalles .
SoT funciona en dos etapas:
- Etapa de esqueleto: Se le pide al LLM que genere un esquema o esqueleto de la respuesta, usualmente en forma de una lista de puntos cortos.
- Etapa de expansión de puntos: El modelo expande cada punto del esqueleto en paralelo. Esto se puede lograr mediante llamadas a la API en paralelo o decodificación por lotes.
Este enfoque de paralelización ofrece mejoras de velocidad sustanciales, logrando una aceleración de más de 2 veces en 8 de 12 modelos de lenguaje evaluados, y en algunos casos, incluso mejorando la calidad de la respuesta al forzar una planificación previa .
Ejemplo de prompt SoT (Etapa de esqueleto):Eres un organizador responsable únicamente de dar el esqueleto (no el contenido completo) para responder la pregunta. Proporciona el esqueleto en una lista de puntos (numerados 1., 2., 3., etc.). En lugar de una oración completa, cada punto debe ser muy corto, con solo 3-5 palabras.
Pregunta: ¿Cómo puedo mejorar mis técnicas de gestión del tiempo?
Esqueleto:
1.
3. El Futuro es multimodal y adaptativo
En 2026, el prompt engineering ya no se limita al texto. La capacidad de los modelos para procesar e integrar múltiples modalidades (texto, imágenes, audio, video) y adaptar las estrategias de prompting dinámicamente está redefiniendo el campo.
Prompting Multimodal
El prompting multimodal es la práctica de diseñar entradas que combinan diferentes tipos de datos. Esto permite casos de uso que eran imposibles con texto solo, como analizar un documento escaneado, describir las tendencias en un gráfico o generar código a partir de un boceto visual.
Una arquitectura efectiva es el stack de 3 capas (Contexto-Instrucción-Modalidad) :
- Capa 1 (Contexto): Define el rol del IA, el trasfondo y las restricciones.
- Capa 2 (Instrucción): Contiene la tarea específica, coordinando explícitamente entre las diferentes modalidades (p. ej., «Primero, analiza los elementos visuales en [IMAGEN], luego, basándote en ese análisis y en [TEXTO], calcula…»).
- Capa 3 (Modalidad): Define explícitamente los tipos de entrada y las relaciones esperadas en la salida.
El impacto de esta técnica es medible. Amazon, al implementar un enfoque multimodal en su búsqueda visual, logró una mejora relativa del 4.95% en las tasas de clics de las coincidencias de imágenes .
Prompting Adaptativo
El futuro del prompt engineering apunta hacia sistemas que se optimizan a sí mismos. El prompting adaptativo es un enfoque donde el sistema de IA refina o selecciona dinámicamente la mejor técnica de prompt para una tarea determinada, basándose en el contexto y la retroalimentación.
Un estudio exhaustivo sobre 13 MLLM y 24 tareas concluyó que «ningún método de prompting optimiza uniformemente todos los tipos de tareas». En cambio, las estrategias adaptativas que combinan guía basada en ejemplos con razonamiento estructurado selectivo son esenciales para mejorar la robustez y la precisión . Esto significa que los sistemas de 2026 no dependerán de un único «mejor» prompt, sino de un repertorio de técnicas que pueden aplicar de manera inteligente.
4. Desafíos y consideraciones éticas
A pesar de los avances, el prompt engineering enfrenta desafíos persistentes. La fragilidad de los prompts (un prompt optimizado para un modelo puede no funcionar en otro o tras una actualización), la gestión del contexto en ventanas cada vez más grandes y el coste computacional de técnicas complejas como ToT o GoT son áreas de investigación activa.
Desde una perspectiva ética, es fundamental diseñar prompts que minimicen los sesgos, eviten la generación de contenido dañino y promuevan la transparencia . Un prompt bien diseñado no solo busca la precisión, sino que también incorpora «barandillas» para guiar al modelo hacia respuestas justas y responsables.
A partir de ahora
El prompt engineering en 2026 es una disciplina sofisticada que combina la creatividad con el rigor científico. Las técnicas avanzadas como Tree of Thoughts, Graph of Thoughts, Chain of Verification y Skeleton of Thought han demostrado empíricamente su capacidad para desbloquear nuevos niveles de razonamiento, fiabilidad y eficiencia en los LLM. La transición hacia el prompting multimodal y adaptativo marca la siguiente frontera, donde la interacción con la IA se vuelve más contextual, dinámica e inteligente.
Dominar estas técnicas ya no es una ventaja competitiva, sino un requisito fundamental para cualquiera que busque aprovechar todo el potencial de la inteligencia artificial en la investigación, los negocios y el desarrollo creativo. El respaldo verificable de su eficacia, a través de benchmarks y casos de uso reales, confirma que estamos ante una evolución tangible y medible en la forma en que colaboramos con las máquinas.

