El universo de la generación de imágenes mediante inteligencia artificial ha experimentado una expansión sin precedentes. Modelos de código abierto cada vez más potentes permiten a artistas, desarrolladores y entusiastas crear visuales asombrosos a partir de simples descripciones de texto. Sin embargo, esta potencia tiene un coste: la memoria de vídeo (VRAM) de la GPU, que se ha convertido en el principal factor limitante para ejecutar estos modelos localmente.
Este análisis ofrece una comparativa de los mejores modelos de texto-a-imagen de código abierto disponibles en 2026, clasificados según los requisitos de VRAM. El objetivo es proporcionar una guía clara para que puedas elegir el modelo más adecuado en función de tu hardware, sin recurrir a información no verificada y basándonos exclusivamente en datos técnicos y benchmarks disponibles.
Factores clave que determinan el consumo de VRAM
Antes de comparar los modelos, es fundamental entender qué componentes y técnicas influyen en el uso de la VRAM. No se trata solo del tamaño del modelo, sino de una combinación de factores.
1. Arquitectura del modelo y sus componentes
La mayoría de los modelos de generación de imágenes modernos, como Stable Diffusion, se componen de varias partes, cada una con su propio consumo de memoria:
- UNet: Es el corazón del proceso de difusión, encargado de eliminar el «ruido» de una imagen latente para dar forma al resultado final. Su tamaño es uno de los mayores contribuyentes al uso de VRAM.
- Codificador de Texto (Text Encoder): Traduce el prompt de texto a un formato que el UNet pueda entender. Modelos avanzados como SDXL o Stable Diffusion 3 utilizan múltiples y enormes codificadores de texto (ej. CLIP ViT-L, OpenCLIP, T5-XXL), que pueden consumir varios gigabytes de VRAM por sí solos .
- Autoencoder Variacional (VAE): Comprime las imágenes a un «espacio latente» de menor dimensión para que el UNet trabaje de forma más eficiente y luego decodifica el resultado final a una imagen visible.
Modelos más recientes como la serie FLUX utilizan arquitecturas basadas en Transformers (DiT – Diffusion Transformers), que, aunque potentes, también son intensivas en memoria .
2. Cuantización: El arte de reducir la precisión
La cuantización es una técnica crucial para reducir el consumo de VRAM. Consiste en disminuir la precisión numérica de los pesos del modelo. La contrapartida es una posible, aunque a menudo mínima, pérdida de calidad.
- FP32 (Precisión Completa): El estándar original, consume más memoria.
- FP16/BF16 (Media Precisión): Reduce el tamaño del modelo a la mitad en comparación con FP32, convirtiéndose en el estándar para la inferencia en GPUs de consumo .
- INT8/FP8 (8-bit): Reduce el tamaño a una cuarta parte de FP32. Formatos como FP8 son especialmente útiles para los codificadores de texto, permitiendo ejecutar modelos como SD3 en hardware más modesto .
- 4-bit (NF4, etc.): Formatos de 4 bits como NF4 permiten ejecutar modelos muy grandes, como FLUX.1, en GPUs con tan solo 8 GB de VRAM, algo que sería imposible en FP16 .
La elección del formato de cuantización es, por tanto, tan importante como la elección del modelo en sí mismo para ajustarse a un presupuesto de VRAM limitado.
Benchmark de modelos por nivel de VRAM
A continuación, se desglosan los modelos recomendados según la capacidad de VRAM de tu GPU, desde el hardware de consumo más común hasta las estaciones de trabajo profesionales.
Nivel 1: GPUs de consumo (6-8 GB VRAM)
Este es el rango más común para los jugadores y entusiastas. Aunque limitado, permite acceder a modelos muy capaces gracias a las optimizaciones.
| Modelo | Requisito de VRAM | Observaciones y Recomendaciones |
| Stable Diffusion 1.5 | ~4-6 GB | Es el punto de partida ideal. Ligero, rápido y con un ecosistema gigantesco de modelos afinados (LoRAs) y herramientas. Funciona de manera óptima en este rango. |
| Stable Diffusion 3 Medium | ~5-8 GB | Sorprendentemente accesible. Utilizando la versión con codificadores de texto en formato fp8, puede funcionar en GPUs de 6 GB y cómodamente en las de 8 GB, ofreciendo una calidad de imagen y comprensión de prompts muy superior a SD1.5. |
| SDXL (con optimizaciones) | ~8 GB (mínimo) | Es posible ejecutarlo, pero estarás en el límite. El modelo base ocupa casi 7.5 GB. Técnicas como el model offloading (descargar partes del modelo a la RAM del sistema) son necesarias, pero provocan una ralentización drástica . No se recomienda para una experiencia fluida. |
| FLUX.1-schnell (cuantizado) | ~8 GB (con NF4) | Solo es viable mediante una cuantización agresiva a 4 bits (NF4). Aunque la calidad puede ser ligeramente inferior a formatos de mayor precisión, permite acceder a la avanzada arquitectura de FLUX en hardware de consumo. |
| FLUX.2 (con optimizaciones) | ~8 GB | Existen informes de usuarios que han logrado ejecutar FLUX.2 en 8 GB de VRAM, probablemente utilizando configuraciones específicas y flujos de trabajo optimizados en ComfyUI. El rendimiento puede ser lento. |
Nivel 2: GPUs de gama Media-Alta (12-16 GB VRAM)
Este rango ofrece un equilibrio excelente entre coste y rendimiento, desbloqueando la capacidad de ejecutar la mayoría de los modelos modernos sin grandes compromisos.
| Modelo | Requisito de VRAM | Observaciones y Recomendaciones |
| SDXL (Base + Refiner) | ~12 GB | Este es el punto dulce para SDXL. Permite cargar el modelo base y el refinador simultáneamente, además de usar herramientas como ControlNet sin problemas de memoria, logrando resultados de alta calidad a buena velocidad. |
| Stable Diffusion 3.5 Large | ~10-12 GB | La versión grande de SD3.5 requiere unos 9.9 GB sin los codificadores de texto. Con ellos, encaja bien en una GPU de 12 GB, especialmente si se usan versiones optimizadas de los codificadores. |
| AuraFlow | ~12 GB (FP16) | Este potente modelo basado en flujo requiere una GPU robusta. La versión fp16 necesita unos 12 GB para funcionar, lo que lo hace inaccesible para el nivel anterior pero ideal para este . Un usuario reportó un uso máximo de 9.7 GB, pero 12 GB es una recomendación más segura. |
| FLUX.1-schnell (INT8/FP8) | ~16 GB | Con 16 GB de VRAM, puedes ejecutar la versión schnell con cuantización a 8 bits (Q8 o FP8), que ofrece una calidad casi idéntica a la versión completa FP16 pero con un menor consumo de memoria y mayor velocidad . |
| FLUX.2-klein | ~13 GB | La variante klein de FLUX.2 está diseñada para ser más ligera, requiriendo alrededor de 13 GB de VRAM. Es una excelente opción para obtener la calidad de FLUX.2 en hardware que no llega a los 24 GB. |
Nivel 3: GPUs profesionales y de Alta Gama (24 GB+ VRAM)
Para aquellos que no quieren compromisos. Con 24 GB o más, puedes ejecutar prácticamente cualquier modelo de código abierto en su máxima calidad y velocidad.
| Modelo | Requisito de VRAM | Observaciones y Recomendaciones |
| FLUX.1-schnell (FP16) | ~24 GB | Para ejecutar la versión schnell en su precisión nativa (FP16/BF16) y a una velocidad decente, se necesitan al menos 24 GB de VRAM. Esto garantiza la máxima calidad y rendimiento del modelo . |
| FLUX.1-dev | ~24 GB+ | La versión para desarrolladores dev) de FLUX.1 es aún más exigente, con una recomendación mínima de 24 GB de VRAM para un rendimiento óptimo . |
| AuraFlow (sin optimizar) | Hasta 35 GB | Algunos informes indican que AuraFlow puede llegar a consumir hasta 35 GB de VRAM en ciertas configuraciones, lo que lo sitúa en el territorio de las GPUs profesionales de muy alta gama como la RTX A6000 . |
| Todos los demás modelos | N/A | Con 24 GB o más, todos los modelos mencionados en los niveles anteriores (SDXL, SD3, etc.) funcionarán sin ninguna restricción de memoria, permitiendo el uso de lotes de imágenes más grandes (batch size), resoluciones más altas y flujos de trabajo complejos. |
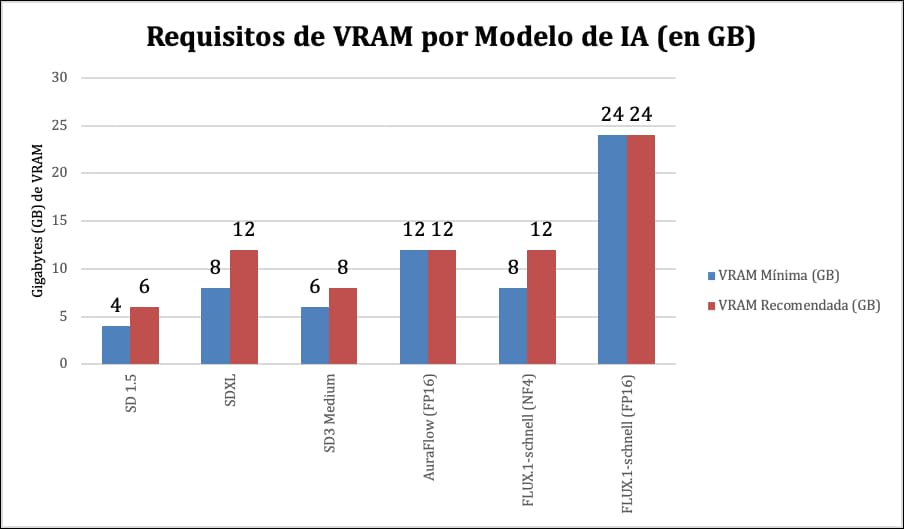
Visualización comparativa de requisitos de VRAM
El siguiente gráfico resume los requisitos mínimos y recomendados de VRAM para los modelos más populares, asumiendo configuraciones de uso común (FP16 para la mayoría, salvo indicación). Esto ayuda a visualizar rápidamente dónde se sitúa cada modelo en el espectro del hardware.
Modelo correcto para tu GPU
La elección del modelo de IA de texto-a-imagen de código abierto en 2026 depende directamente de la VRAM disponible. No existe un «mejor» modelo universal, sino el modelo más adecuado para cada configuración de hardware.
- Para usuarios con 6-8 GB de VRAM, Stable Diffusion 1.5 sigue siendo una opción sólida y fiable, mientras que Stable Diffusion 3 Medium emerge como el claro ganador en términos de calidad/rendimiento, siempre que se utilicen las optimizaciones adecuadas (como codificadores FP8).
- Con 12-16 GB de VRAM, el ecosistema se abre por completo. SDXL se convierte en la opción estándar para una alta calidad y personalización, mientras que modelos más avanzados como AuraFlow y las versiones cuantizadas de FLUX.1 son perfectamente viables, ofreciendo una fidelidad de prompt superior.
- Aquellos con 24 GB de VRAM o más tienen el lujo de no preocuparse por la memoria. Pueden ejecutar los modelos más potentes como FLUX.1-dev o FLUX.1-schnell en su máxima precisión, explorando la vanguardia de la generación de imágenes sin compromisos.
La clave del éxito reside en comprender las herramientas de optimización, especialmente la cuantización. Dominar el uso de formatos como FP8 o NF4 puede ser la diferencia entre poder ejecutar un modelo de última generación o quedarse atrás. A medida que los modelos continúan creciendo en tamaño y complejidad, la gestión eficiente de la VRAM seguirá siendo la habilidad más importante para cualquier entusiasta de la IA generativa local.