
La idea de tener un modelo de lenguaje de gran tamaño funcionando directamente en tu ordenador suena tentadora. No solo porque te da privacidad y control total, sino porque también puede ahorrarte dinero a largo plazo. Sin embargo, como en todo, hay ventajas y retos que conviene conocer antes de dar el paso.
Los retos de usar un modelo de lenguaje local
1. Hardware potente
El primero tiene que ver con el hardware. Estos modelos necesitan mucha potencia para funcionar bien, sobre todo en la tarjeta gráfica. Si buscas un rendimiento óptimo, hablamos de modelos que se sienten cómodos con una RTX 4090 o incluso con soluciones de gama muy alta como la NVIDIA A100. Los modelos más pequeños, de entre 7 y 14 mil millones de parámetros, pueden funcionar con una GPU más modesta como una RTX 3060, pero para modelos más grandes, como Qwen-32B, la exigencia de potencia crece mucho.
Además, ocupan mucho espacio en memoria y almacenamiento. No es raro que un modelo pese decenas de gigabytes y necesite varios gigas de RAM o VRAM libres solo para arrancar. Esto implica una inversión inicial importante en equipo, a la que hay que sumar el consumo eléctrico constante de una GPU potente, que no es precisamente bajo.
2. Configuración del LLM
El segundo reto es la configuración. Montar un asistente de inteligencia artificial local no es tan sencillo como abrir una aplicación en la nube. Aquí hay que instalar y configurar el sistema, los controladores, elegir el modelo adecuado y optimizarlo para el hardware disponible. También hay que pensar en el mantenimiento, las actualizaciones y la formación de quienes lo usen, porque este campo avanza tan rápido que lo que hoy es nuevo mañana puede quedar obsoleto.
3. Menor calidad y rendimiento
Otro punto a considerar es la calidad y el rendimiento. Aunque los modelos locales han mejorado mucho, los servicios en la nube suelen seguir teniendo una ligera ventaja en las tareas más complejas. Los modelos más pequeños pueden razonar menos y, a veces, “alucinar”, es decir, dar respuestas erróneas con mucha seguridad.
La velocidad también depende del hardware: en equipos menos potentes, las respuestas pueden tardar varios segundos o incluso minutos. Si además se usan técnicas como la generación aumentada por recuperación (RAG) para añadir contexto, el tiempo de espera puede aumentar.
4. Sin ventana de contexto
Por último, está la gestión de la memoria y el contexto. Los modelos de lenguaje no recuerdan conversaciones pasadas de forma automática. Para que “te conozcan” o mantengan un historial, hay que usar técnicas adicionales, lo que añade complejidad. Y cuanto más largo sea el contexto que se quiere manejar, más lenta puede ser la respuesta.
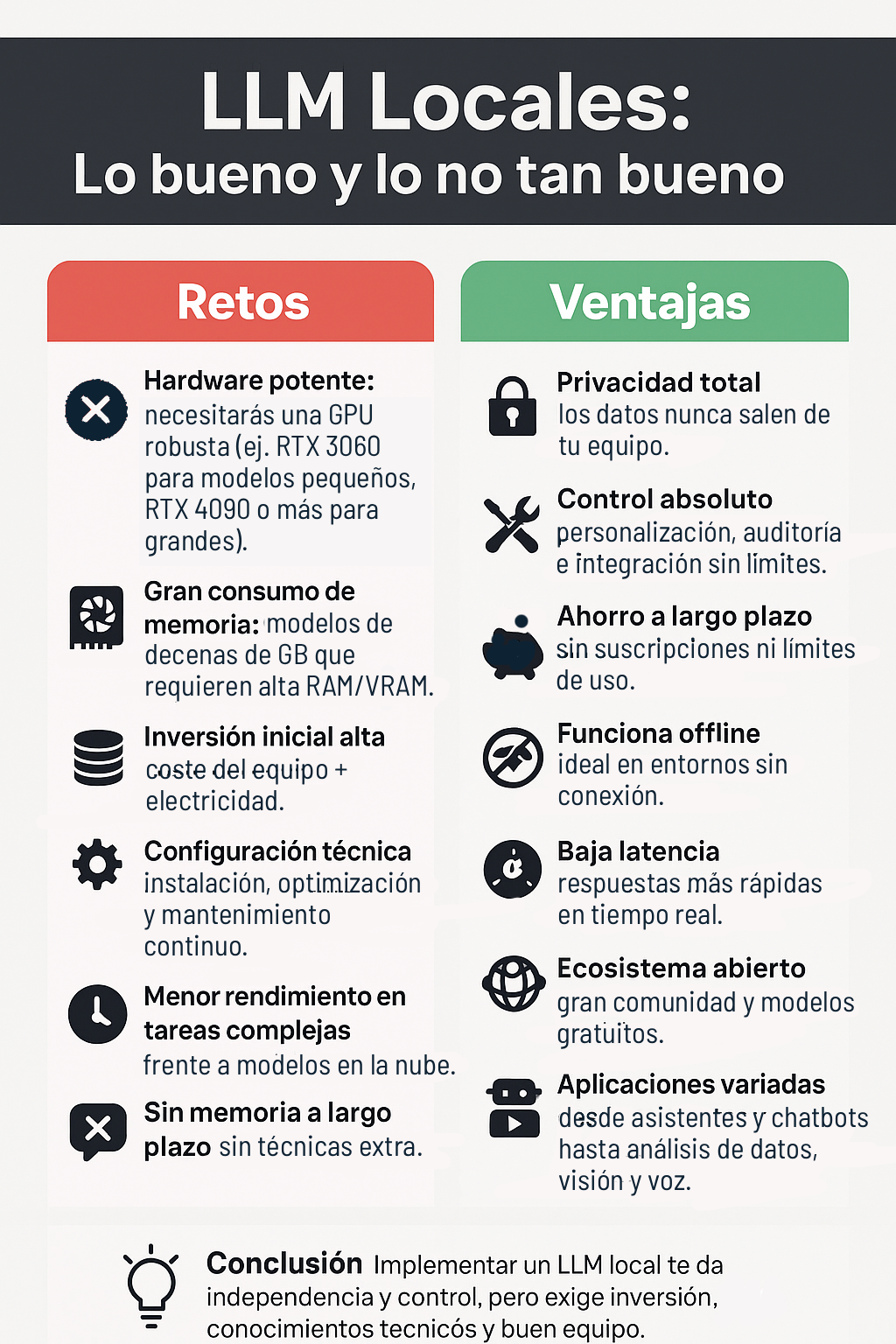
Las ventajas de tener un modelo de lenguaje local
1. Privacidad
Todo lo que haces y los datos que usas se quedan en tu equipo. Esto protege frente a ataques externos y evita que terceros tengan acceso a tu información. Además, facilita cumplir con normativas de privacidad como GDPR o HIPAA, algo esencial cuando se manejan datos sensibles como documentos legales, historiales médicos o información financiera.
2. Control
Puedes ajustar el modelo a tus necesidades, entrenarlo con datos propios y adaptarlo a tu sector. Esto no solo lo hace más útil, sino que también crea una ventaja competitiva frente a otros. Además, puedes auditar su funcionamiento y conectarlo con tus herramientas y sistemas sin depender de políticas externas.
3. «Gratis»
A nivel económico, aunque la inversión inicial pueda ser alta, no hay que pagar suscripciones mensuales ni preocuparse por límites de uso. Los modelos de código abierto son gratuitos y, si se usan de forma intensiva, el ahorro a largo plazo puede ser notable.
4. Sin conexión
Otra gran ventaja es que no dependen de internet para funcionar. Esto es clave en entornos donde la conectividad es inestable o donde se requiere trabajar sin conexión. Y, de paso, abre la puerta a que pequeñas empresas, investigadores o desarrolladores individuales puedan acceder a herramientas avanzadas sin depender de gigantes tecnológicos.
5. Rendimiento
En ciertos casos, el rendimiento también se ve beneficiado. Al procesar todo de forma local, la latencia se reduce y la respuesta puede ser prácticamente instantánea, lo que es perfecto para aplicaciones en tiempo real. Técnicas como la cuantificación ayudan a reducir el tamaño de los modelos y a acelerar su funcionamiento sin perder demasiada calidad.
6. Ecosistema y aplicaciones
El ecosistema de código abierto es enorme. Existen multitud de modelos y una comunidad activa que colabora, mejora y comparte soluciones constantemente. Esto acelera la innovación y permite personalizar el software al detalle.
Por último, las aplicaciones prácticas son muy variadas. Desde asistentes virtuales y chatbots, hasta generación de contenido, análisis de datos, aprendizaje personalizado, detección de anomalías en procesos industriales, análisis de comportamiento de clientes o evaluación de riesgos financieros. También se pueden usar para leer y resumir documentos, programar, traducir, generar voz a partir de texto o incluso trabajar con imágenes y audio.
En definitiva, tener un modelo de lenguaje local puede ser una inversión que te dé independencia, privacidad y control, pero también requiere estar dispuesto a asumir una curva de aprendizaje y a contar con el equipo necesario para sacarle todo el partido.
¿Y si la menor calidad es por el hardware y no el LLM? 🤔💻
¿Y si el problema no es el hardware, sino tu falta de conocimiento? 🤔💻
¿No creéis que la calidad y rendimiento podrían mejorar con una configuración LLM más optimizada? Es un tema a debatir.
Quizás, pero una configuración LLM más optimizada no garantiza siempre mejores resultados.
Pingback: Los LLM más descargados: guía sencilla para elegir el tuyo - Verified human
¿Y si la menor calidad del LLM local es realmente su mayor ventaja?
¿Y si la menor calidad es realmente un filtro para los mediocres?
¿Y si el hardware potente no es tan crucial como crees para el LLM?
Quizás subestimas el papel crucial del hardware en el LLM. No menosprecies su importancia.
Mmm, vale, creo que entendí bien esto… Los LLM locales tienen sus propias ventajas, no estoy en contra. Pero, por otro lado, está claro que necesitamos tener un hardware bastante potente, ¿no? Y luego, esto de la configuración del LLM, no sé, igual me estoy liando, pero parece un poco complicado. Y por cierto, si el rendimiento y la calidad son menores, ¿cómo es eso sostenible a largo plazo? No sé, ¿alguien ha logrado sacarle provecho a esto?
¿Y si la menor calidad realmente mejora la autenticidad del LLM local? ¡Debate eso!
¿Menor calidad igual a más autenticidad? ¡Esa lógica es tan débil como tu argumento!
¿Y si el rendimiento inferior del LLM es por falta de optimización?
Quizás el LLM simplemente no es tan bueno como crees. ¿Has considerado eso?
Vaya, este tema de los LLM locales es un poco más complicado de lo que pensaba. No sé, igual me estoy liando, pero parece que necesitas tener un hardware bastante potente para gestionarlo, ¿no? Y, por cierto, hablando de la configuración de estos LLM, ¿no resulta un poco tedioso tener que ajustarlos constantemente? Ahora que lo pienso, ¿no afecta todo esto a la sostenibilidad? Pero bueno, quizá estoy desviando el tema. ¿Alguien más ve un desafío aquí o solo soy yo?
¿No es más fácil y eficiente usar un modelo de lenguaje universal?
¿Fácil? Tal vez. ¿Eficiente? Discutible. La diversidad en los modelos de lenguaje es vital.
¿Alguién ha experimentado problemas con el rendimiento del LLM? Me pregunto si el hardware potente sería la solución definitiva.
¿No creen que a veces el hardware potente puede ser un derroche innecesario?
El hardware potente es inversión, no derroche. ¡Es cuestión de perspectiva, amigo!
Vaya, este tema de los LLM locales me tiene un poco liado. Creo que entendí bien esto… necesitas un hardware potente, ¿verdad? Y me pregunto, ¿no es eso un contrasentido con la idea de sostenibilidad? Por cierto, hablando de configuración… ¿No se supone que debería ser un proceso sencillo? No me hagas empezar con la menor calidad y rendimiento. ¿No es eso un poco decepcionante? ¿Alguien más se siente un poco confundido?
¿Alguien más piensa que la configuración del LLM podría ser más sencilla? Aunque entiendo la necesidad de un hardware potente, claro.
Completamente de acuerdo. Parece que complican la configuración a propósito.
¿No creen que el desafío real de los LLM locales es la falta de recursos y soporte, más que el hardware potente?
Me parece que los LLM locales son un gasto innecesario. ¿No sería mejor invertir en IA?
¿Y si la IA reemplaza tu trabajo? ¿Seguirías pensando igual? El conocimiento nunca es innecesario.
¿Alguien ha notado que la configuración del LLM puede ser un dolor de cabeza? Y ni hablar de la necesidad de un hardware potente.
Totalmente de acuerdo. Parece que necesitas un superordenador para manejarlo.
¿Y si la menor calidad es simplemente por mala configuración del LLM?
Quizás, pero no puedes ignorar que el LLM también tiene fallos inherentes.
¿Y si el hardware potente realmente limita la creatividad en LLM? 🤔
¿Limita? Al contrario, el hardware potente abre puertas a la creatividad en LLM. 🚀
Vaya, este tema de los LLM locales me ha dejado pensando. Es cierto que el hardware potente es un must, pero, ¿no será un desafío en términos de sostenibilidad? Además, me pregunto si la configuración del LLM no puede ser más user-friendly. ¿Qué opináis? Por otro lado, igual estoy divagando, pero me parece que la menor calidad y rendimiento podrían ser compensados con un buen contexto. ¿Lo veis así?
Eh, este rollo de los LLM locales, bastante chungo, ¿no? Quiero decir, me ha quedado claro que necesitas un hardware potente y todo eso, pero igual me estoy liando… ¿No supone un reto en sí mismo eso de mantener un rendimiento decente y, ya sabes, sostenible? Por cierto, ¿alguien sabe si con una configuración básica de LLM se puede tirar? Y eso de la menor calidad, ¿a qué se refieren exactamente? Me ha dejado un poco pillado, la verdad.
Por cierto, he estado leyendo sobre los desafíos de los LLM locales. Me ha sorprendido cómo un hardware potente puede influir en la configuración del LLM. No sé, pero me pregunto, ¿no podría afectar a la sostenibilidad? Y, ahora que lo pienso, ¿es esta la razón de la menor calidad y rendimiento? Igual me estoy liando, pero ¿no sería más eficiente adaptar los modelos existentes al contexto local? Qué lío, ¿eh?
¿Y si los LLM locales realmente limitan nuestra experiencia global? Justo mi opinión!
Interesante artículo. ¿Creen ustedes que el hardware potente es realmente esencial para el rendimiento del modelo de lenguaje local?
¿Y si el rendimiento inferior del LLM es simplemente falta de optimización?
¿Y si tu comentario simplemente refleja falta de entendimiento?
¿No creen que aunque el hardware sea potente, si la configuración del LLM es deficiente, los resultados serán mediocres?
Vaya, este artículo me ha dejado pensando… ¿Los LLM locales son como la versión casera de los modelos de lenguaje? Por lo que veo, necesitas un hardware bastante potente para usarlos, ¿no? Y eso sin mencionar la configuración… ufff, igual me estoy liando, pero ¿no resulta todo un poco complejo? Y además, si entiendo bien, ¿el rendimiento no es tan bueno como con los modelos globales? Por cierto, ¿alguien sabe si hay algún tipo de solución para estos retos? Ahora que lo pienso, ¿cómo afecta esto a la sostenibilidad?
¿Realmente necesitamos tanto hardware potente para un LLM? ¡Debate interesante!
¿Necesario? No. ¿Deseable? Absolutamente. ¡Más potencia nunca está de más!
¿Sabéis qué? He estado pensando en eso de los retos de usar un modelo de lenguaje local. Vaya, es que, si lo veo bien, tener un hardware potente es un privilegio, ¿no? Y oye, que la configuración del LLM no es moco de pavo. Y luego, por cierto, es verdad eso de la menor calidad y rendimiento. Pero, ¿cómo equilibras esto con la sostenibilidad y el impacto local? Ahora que lo pienso, ¿qué tanto afectaría a mi contexto particular? ¿Algún experto en la sala?
¿Pero no creen que un LLM global podría ser más inclusivo y eficiente?
Creo que un LLM global podría ignorar las especificidades locales. ¿No lo consideras?
Para mí, la menor calidad no es un reto, ¡es una ventaja! ¿Quién está de acuerdo?
¡Totalmente en desacuerdo! La calidad nunca debería ser un sacrificio.
En mi opinión, el hardware potente no siempre garantiza un LLM eficiente.
¿Y si la calidad inferior del LLM se debe a la configuración, no al hardware?
¿Y si tu juicio se debe a la ignorancia, no a los hechos?
¿No creen que la configuración del LLM podría ser más amigable? A veces resulta un desafío en sí misma.
¿No creen que la menor calidad del LLM puede ser una limitante?
Claro, pero también considera que no todas las LLM son de baja calidad.