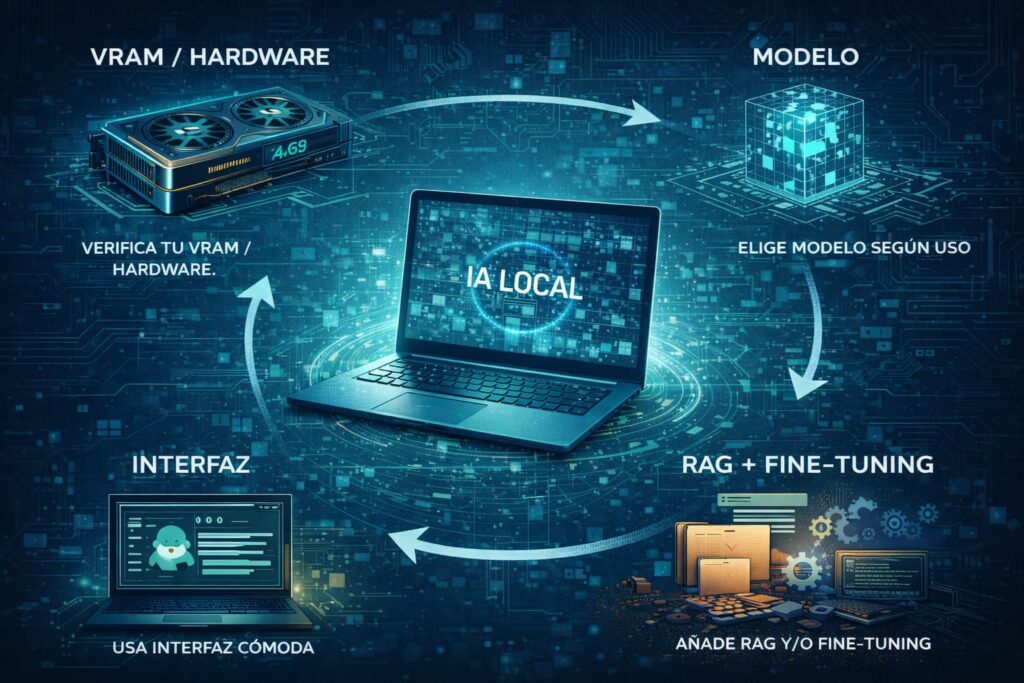
Ahora que ya conoces las ventajas y las sombras de la IA local, toca la parte divertida: cómo elegir el modelo, el hardware y el software para montarte tu propio “ChatGPT en casa” de forma realista y sin ahogarte en tecnicismos.
¿Qué máquina tienes? La VRAM es la reina
Lo primero no es elegir el modelo, sino ser honesto con tu hardware. En IA local, la palabra clave es VRAM: la memoria de tu tarjeta gráfica. Cuanta más tengas, más grande y potente puede ser el modelo que ejecutes con fluidez.
Como regla orientativa:
- Sin GPU dedicada (solo CPU):
- Puedes usar modelos pequeños y muy optimizados.
- Irán más lentos, pero sirven para escribir, resumir y tareas ligeras.
- 4–6 GB de VRAM:
- Modelos ligeros que se defienden bien en texto general.
- Ideal para empezar y experimentar.
- 8–12 GB de VRAM:
- Punto dulce para muchos usuarios.
- Permite modelos medianos con muy buen rendimiento en escritura, programación y análisis de documentos.
- 16 GB de VRAM o más:
- Ya puedes plantearte modelos grandes y contextos amplios.
- La experiencia se acerca mucho a los servicios premium en la nube.
No hace falta tener “la mejor gráfica del mercado”, pero sí entender que el modelo tiene que ajustarse a tu máquina, no al revés.
¿Para qué la quieres? El modelo según tu caso de uso
La pregunta clave no es “¿cuál es el mejor modelo?”, sino “¿para qué la voy a usar de verdad?”.
Algunos perfiles típicos:
- Escritura y contenido (blogs, guiones, correos, copy):
- Prioriza modelos buenos en lenguaje natural, creativos y con buen español.
- No necesitas lo más grande, pero sí algo equilibrado entre calidad y velocidad.
- Programación y automatización:
- Elige modelos entrenados o afinados para código.
- Aunque sean algo más pesados, lo ganarás en calidad de sugerencias y comprensión de repositorios.
- Análisis de documentos y trabajo de conocimiento:
- Aquí el truco no es solo el modelo, sino cómo lo conectas a tus archivos.
- Un modelo mediano con buena integración con tus PDFs, notas y bases de datos suele ser más útil que un modelo enorme “a ciegas”.
- Uso mixto (un poco de todo):
- Busca un modelo generalista, con buen rendimiento en texto, razonamiento y algo de código.
- Es lo más parecido a tener un “asistente polivalente” en local.
Piensa en tu IA local como en un miembro de tu equipo: ¿quieres un redactor, un programador, un documentalista o un perfil “todoterreno”? Según eso eliges.
Elige tu “centro de mando” (software de interfaz)
Tener el modelo es solo la mitad del juego. Necesitas una interfaz cómoda para hablar con él, arrancar y parar instancias, gestionar chats, etc.
Las opciones típicas suelen ofrecer:
- Interfaz estilo “chat” en el navegador o en una app de escritorio.
- Gestión de varios modelos (puedes ir probando sin volverte loco).
- Posibilidad de conectar la IA con otras herramientas: navegador, editor de código, automatizaciones, etc.
Lo ideal es que el software elegido:
- Sea fácil de instalar (idealmente, siguiente-siguiente y poco más).
- Tenga comunidad activa y documentación básica.
- Te permita empezar en “modo simple” y luego ir activando opciones avanzadas según te sientas cómodo.
Piensa en esto como elegir la “cabina de mando” de tu avión: el motor (el modelo) puede ser potente, pero si la cabina es un caos no vas a disfrutar del vuelo.
Lleva tu IA al siguiente nivel: con tus propios datos
Una vez que tienes tu IA local funcionando, llega el momento en que te preguntas:
“Vale, escribe bien, pero… ¿cómo hago que entienda mis documentos, mis procesos y mi negocio?”
Aquí entran dos grandes enfoques: RAG y fine-tuning.
RAG: darle memoria externa
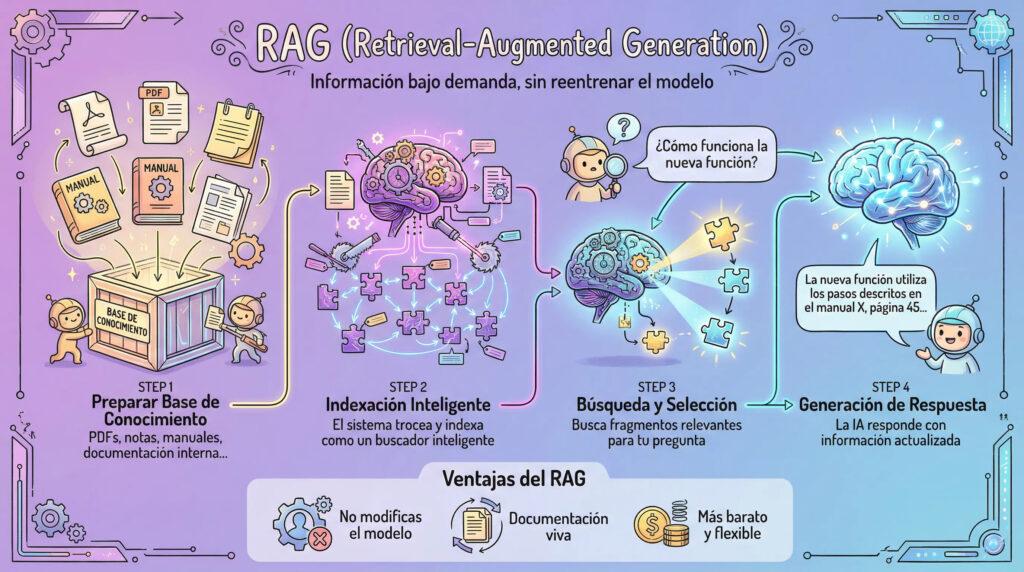
RAG (Retrieval-Augmented Generation) suena complicado, pero la idea es sencilla:
en lugar de “meterlo todo” dentro del modelo, lo dejas fuera y se lo vas pasando bajo demanda.
Funciona más o menos así:
- Preparas tu base de conocimiento: PDFs, notas, manuales, documentación interna…
- Un sistema “trocea” esos documentos y los indexa (como un buscador inteligente).
- Cuando haces una pregunta, el sistema busca primero en tus documentos, selecciona los fragmentos relevantes y se los pasa al modelo junto con tu pregunta.
- La IA responde usando esa información actualizada, sin haber tenido que reentrenar nada.
Ventajas:
- No modificas el modelo: puedes cambiar y actualizar documentos cuando quieras.
- Es ideal para empresas o proyectos con documentación viva.
- Es más barato y flexible que entrenar un modelo desde cero.
Fine-tuning: enseñarle a hablar como tú
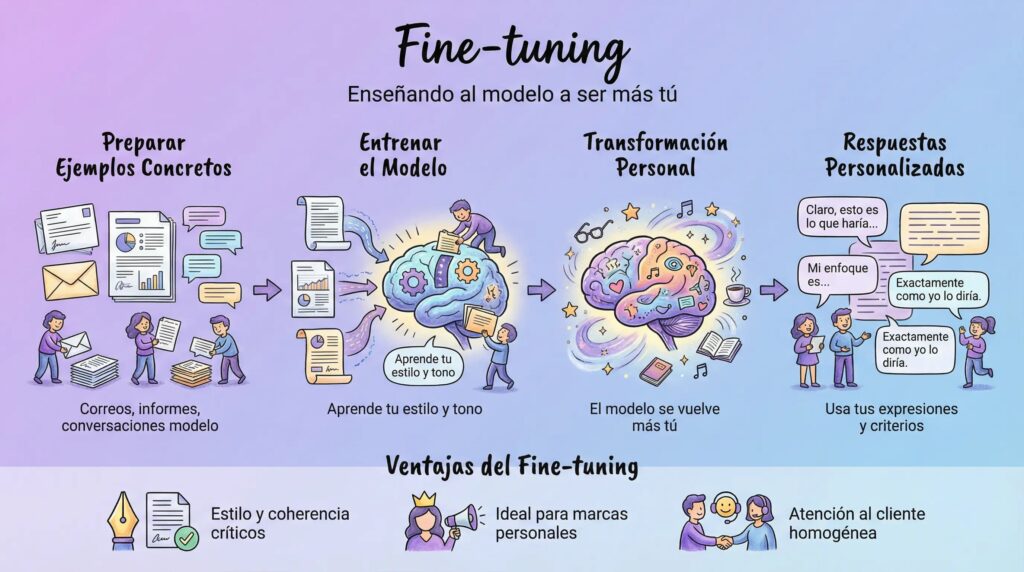
El fine-tuning es otra cosa: aquí sí tocas el modelo. Le das ejemplos concretos (prompts y las respuestas esperadas) para que aprenda tu estilo, tu tono y tu forma de resolver tareas.
Por ejemplo:
- Correos escritos por ti que te gustaría que imite.
- Informes o plantillas que sigan una estructura muy tuya.
- Conversaciones modelo con clientes, con el tipo de respuestas que quieres dar.
Tras el ajuste, el modelo se vuelve más “tú”: usa tus expresiones, prioriza tus criterios y responde más alineado con tu forma de trabajar.
Ventajas:
- Ideal cuando el estilo y la coherencia son críticos.
- Muy útil para marcas personales, atención al cliente o documentación interna homogénea.
RAG vs fine-tuning: ¿cuál uso?
Una forma sencilla de verlo:
- Si tu problema es “quiero que tenga acceso a mucha información que cambia a menudo” → RAG.
- Si tu problema es “quiero que responda como yo, con este tono y estructura” → fine-tuning.
En muchos casos, lo mejor es combinar ambos:
- RAG para que la IA esté “conectada” a tus datos actualizados.
- Un ligero fine-tuning o instrucciones bien pensadas para que mantenga tu estilo y prioridades.
La estrategia híbrida: lo mejor de ambos mundos
La verdadera potencia llega cuando juntas todo:
- Un modelo local ajustado a tu hardware.
- Una interfaz cómoda que te permita usarlo cada día sin fricción.
- RAG para que conozca tu documentación y contexto.
- Fine-tuning ligero (o instrucciones muy bien diseñadas) para que se parezca a tu forma de pensar y comunicar.
Con ese combo, dejas de tener “una IA genérica en tu ordenador” y pasas a tener un asistente muy tuyo, privado, afinado a tu trabajo y sin cuotas mensuales.
Es un camino que se recorre paso a paso, no de golpe. Empieza por montar el modelo, luego añádele interfaz, más tarde conéctalo a tus documentos y, si lo necesitas, da el salto a personalización avanzada.