Gracias a avances exponenciales en hardware y software, dispositivos como el nuevo iPhone 17 Pro no son solo teléfonos, sino verdaderas plataformas de computación neuronal. Este tutorial te guiará a través del proceso de instalación y ejecución de Qwen, una de las familias de modelos de lenguaje (LLM) de código abierto más capaces, directamente en el dispositivo.
Exploraremos dos caminos principales:
- El método sencillo: Utilizando aplicaciones de la App Store que simplifican todo el proceso, ideal para la mayoría de los usuarios.
- El método avanzado: Para desarrolladores y entusiastas que deseen afinar y desplegar sus propias versiones personalizadas de Qwen.
Ambos métodos aprovechan las capacidades sin precedentes del iPhone 17 Pro, garantizando una experiencia fluida y potente que redefine lo que es posible hacer con un smartphone.
El iPhone 17 Pro
Primero debemos analizar el iPhone 17 Pro y el chip A19 Pro, el cual no solo ofrece mejoras en eficiencia, sino que integra una arquitectura diseñada específicamente para la IA.
Según los análisis y benchmarks iniciales, el A19 Pro incorpora aceleradores neuronales directamente en sus núcleos de GPU, permitiendo una ejecución de tareas de IA en el dispositivo mucho más rápida. Combinado con los 12 GB de RAM, el dispositivo puede manejar modelos de miles de millones de parámetros sin problemas, algo impensable hace solo unos años.
Rendimiento esperado: Tokens por segundo
El rendimiento de un LLM se mide a menudo en tokens por segundo (t/s), que representa la velocidad a la que el modelo genera texto. Gracias al chip A19 Pro, el iPhone 17 Pro muestra un rendimiento excepcional. El siguiente gráfico compara el rendimiento estimado de modelos Qwen en el iPhone 17 Pro frente a un predecesor, el iPhone 15 Pro, basándose en datos de herramientas de despliegue como ExecuTorch y Cactus.
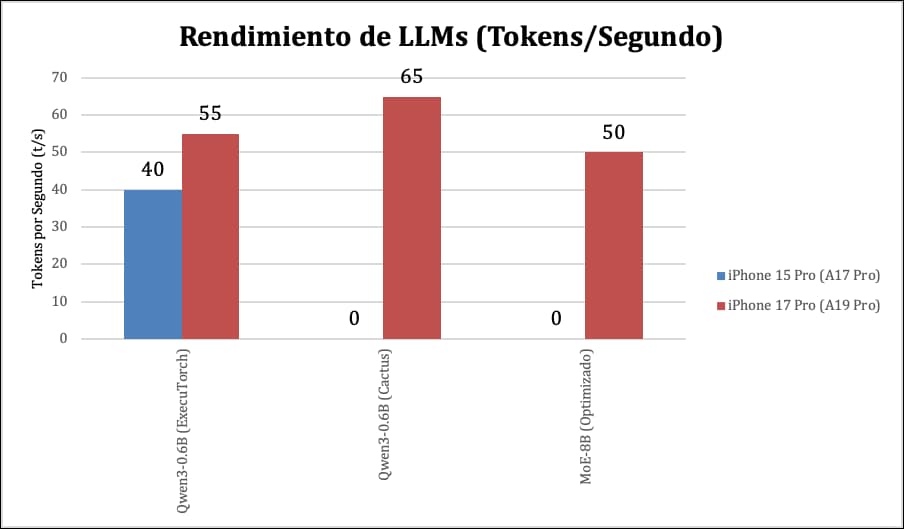
Como muestra el gráfico, el iPhone 17 Pro no solo mejora el rendimiento, sino que lo duplica en algunos casos. Motores de inferencia optimizados como Cactus pueden alcanzar velocidades de 60-70 t/s para un modelo como Qwen3-0.6B, una velocidad que se siente instantánea en una conversación . Esto abre la puerta a aplicaciones de IA conversacional complejas y de respuesta rápida, todo ello de forma 100% local y privada.
Método 1: PocketPal AI
Para la gran mayoría de usuarios que desean experimentar con Qwen sin complicaciones técnicas, la mejor opción es utilizar una aplicación dedicada de la App Store. PocketPal AI se destaca como una de las más robustas y fáciles de usar.
PocketPal AI es una aplicación gratuita y de código abierto que te permite descargar y ejecutar LLMs en formato GGUF directamente en tu iPhone, con integración con el hub de Hugging Face para un acceso sencillo a miles de modelos.
Instalar Qwen con PocketPal AI:
- Instalar la aplicación: Busca «PocketPal AI» en la App Store y descárgala. Es una aplicación gratuita que valora la privacidad, ya que no recopila datos del usuario.
- Explorar y descargar modelos: Abre PocketPal. La aplicación tiene una sección de «Modelos» con una función de búsqueda integrada con Hugging Face. Esto te permite buscar modelos en formato GGUF, que es un estándar para ejecutar LLMs localmente.
- Encontrar un modelo Qwen: En la barra de búsqueda de modelos, escribe Qwen GGUF. Verás una lista de diferentes versiones y tamaños. Para empezar, te recomendamos un modelo de tamaño moderado, como Qwen2.5-1.5B-Instruct-GGUF o similar. Los modelos más pequeños se descargan más rápido y consumen menos recursos, siendo ideales para un primer contacto. Según la comunidad, PocketPal ya soporta modelos Qwen 2.5 y Qwen 3.
- Iniciar una conversación: Una vez que el modelo se haya descargado, aparecerá en tu lista de modelos locales. Simplemente selecciónalo para iniciar un nuevo chat. ¡Listo! Ahora puedes conversar con Qwen de forma totalmente offline, privada y sin coste por uso.
Otras aplicaciones como Locally AI también ofrecen una funcionalidad similar y son una excelente alternativa si deseas explorar otras interfaces.
Método 2: Unsloth y ExecuTorch
Si eres un desarrollador o un entusiasta que desea un control total, como afinar (fine-tuning) un modelo Qwen con tus propios datos o desplegar una versión específica, el camino a seguir es a través de herramientas de desarrollo como Unsloth y ExecuTorch de PyTorch.
Este método es considerablemente más complejo y requiere un Mac, una cuenta de desarrollador de Apple (de pago para dispositivos físicos) y conocimientos básicos de Python y línea de comandos.
El siguiente tutorial se basa en la excelente guía proporcionada por Unsloth AI.
Paso 1: Afinar y exportar el modelo
El primer paso no se realiza en tu Mac, sino en la nube, utilizando un notebook de Google Colab gratuito proporcionado por Unsloth. Este proceso prepara el modelo para que sea eficiente en el móvil.
- Abrir el Notebook: Accede al notebook de Colab para despliegue en móviles. Unsloth soporta Qwen3, Llama3, Gemma3 y más. Acceder a los Notebooks de Unsloth
- Entrenamiento y Cuantización: El notebook utiliza una técnica llamada Quantization-Aware Training (QAT). Esto reduce el tamaño del modelo y optimiza su velocidad, minimizando la pérdida de precisión.
- Exportar a .pte: Al finalizar el proceso, obtendrás dos archivos cruciales: un archivo de modelo como qwen3_0.6B_model.pte (de unos 472 MB) y un archivo tokenizer.json. Estos son los archivos que desplegarás en tu iPhone.
Paso 2: Configurar el entorno en macOS
Ahora, en tu Mac, necesitas preparar el entorno de desarrollo.
1. Instalar Xcode: Descarga e instala Xcode 15 o superior desde la Mac App Store.
2. Instalar herramientas de línea de comandos: Abre la Terminal y ejecuta
xcode-select --install
3. Aceptar Licencia: Ejecuta
sudo xcodebuild -license accept
4. Configurar Cuenta de Desarrollador: En Xcode, ve a Settings > Accounts y añade tu Apple ID. Si aún no lo has hecho, inscríbete en el Apple Developer Program (de pago) para poder instalar la app en tu iPhone físico.
Paso 3: Desplegar en el iPhone 17 Pro
Este es el paso final donde todo se une.
1. Obtener la App de Demo: Clona el repositorio de ExecuTorch y abre el proyecto de ejemplo para iOS, que se encuentra en apple/etLLM.xcodeproj.
2. Conectar tu iPhone: Conecta tu iPhone 17 Pro al Mac con un cable USB y selecciona «Confiar en este ordenador» en el teléfono.
3. Configurar la Firma del Proyecto:
- En Xcode, selecciona el proyecto etLLM.
- Ve a la pestaña Signing & Capabilities.
- Marca «Automatically manage signing» y selecciona tu equipo de desarrollador.
- Importante: Cambia el Bundle Identifier a algo único (ej. com.tunombre.etLLM) para evitar conflictos.
4. Añadir Capacidad de Memoria: En la misma pestaña, haz clic en + Capability y añade «Increased Memory Limit». Esto es esencial para que el LLM tenga suficiente RAM para funcionar.
5. Activar Modo Desarrollador en el iPhone:
- Ve a Ajustes > Privacidad y seguridad > Modo de desarrollador en tu iPhone y actívalo. El teléfono se reiniciará.
6. Compilar y Ejecutar: En Xcode, selecciona tu iPhone 17 Pro como destino y pulsa el botón de Play (▶️). La primera vez podría fallar mientras se configuran los perfiles. Vuelve a intentarlo.
7. Transferir los Archivos del Modelo:
- Una vez que la app etLLM esté instalada y ejecutándose en tu iPhone, abre Finder en tu Mac.
- Selecciona tu iPhone en la barra lateral y ve a la pestaña «Archivos».
- Expande la app etLLM y arrastra tus archivos .pte y tokenizer.json a esa carpeta.
8. Abre la app etLLM en tu iPhone, carga el modelo y el tokenizador desde la interfaz, y comienza a chatear con tu LLM personalizado.
Comparativa de métodos y modelos
La elección del método y del modelo depende de tus necesidades. Aquí tienes una tabla comparativa para ayudarte a decidir.
Tabla comparativa de métodos de despliegue
| Método | Facilidad de Uso | Flexibilidad | Requisitos | Coste |
| PocketPal AI | ★★★★★ (Muy fácil) | ★★★☆☆ (Limitado a modelos GGUF) | Solo el iPhone | Gratis |
| MLC Chat | ★★★★☆ (Fácil) | ★★★★☆ (Permite añadir modelos, pero es complejo) | Solo el iPhone (para uso básico) | Gratis |
| Unsloth + ExecuTorch | ★☆☆☆☆ (Muy difícil) | ★★★★★ (Control total, fine-tuning) | Mac, cuenta de desarrollador de pago, conocimientos técnicos | Coste de la cuenta de desarrollador (~$99/año) |
Modelos Qwen recomendados para el iPhone 17 Pro
- Qwen3-0.6B / Qwen2.5-1.5B: Ideales para un equilibrio entre velocidad y capacidad. Perfectos para chat general, resúmenes y tareas sencillas. Su bajo consumo de recursos garantiza un rendimiento muy rápido.
- Qwen3-4B: Un modelo más potente que ofrece un razonamiento mejorado y mayor coherencia. Gracias a los 12 GB de RAM del iPhone 17 Pro, este modelo funciona cómodamente, aunque con una velocidad de generación ligeramente inferior a los modelos más pequeños.
- Qwen3-Coder: Si tu interés es la generación de código, las variantes «Coder» de Qwen están específicamente entrenadas para ello y funcionan sorprendentemente bien en el dispositivo.
Tu asistente de IA
La convergencia del hardware del iPhone 17 Pro y los ecosistemas de software como PocketPal, MLC LLM y ExecuTorch ha hecho que la ejecución de LLMs de alto rendimiento como Qwen en un dispositivo móvil sea una realidad práctica y emocionante en 2026.
Para la mayoría, el camino más recomendable es empezar con una aplicación como PocketPal AI por su simplicidad y acceso inmediato a una amplia gama de modelos. Para los desarrolladores y aquellos que buscan la máxima personalización, el flujo de trabajo de Unsloth y ExecuTorch ofrece un poder sin precedentes, permitiendo la creación de experiencias de IA verdaderamente a medida.
Independientemente del camino que elijas, el resultado es el mismo: un asistente de IA potente que vive en tu bolsillo, funciona sin conexión, respeta tu privacidad al 100% y está siempre listo para ayudarte.