Seguro que has oído hablar de ChatGPT, Gemini o Claude. Son Modelos de Lenguaje Grandes (LLM) increíbles, pero funcionan como una «caja negra«: envías una pregunta y recibes una respuesta, sin saber muy bien qué pasa dentro ni tener control sobre tus datos. Aquí es donde entran en juego los LLM de código abierto.
Imagina poder tener una de estas inteligencias artificiales superpotentes instalada directamente en tu ordenador. Un modelo cuyo «cerebro» (su código y sus pesos) es público. Puedes estudiarlo, modificarlo, adaptarlo a tus necesidades específicas y, lo más importante, ejecutarlo de forma local. Esto significa que tus conversaciones y datos privados nunca salen de tu máquina.
Los LLM de código abierto democratizan el acceso a la IA de vanguardia, ofreciendo un nivel de transparencia, personalización y privacidad que los modelos cerrados no pueden igualar.
En 2026, el ecosistema ha madurado hasta un punto en que muchos de estos modelos no solo compiten, sino que superan a sus alternativas comerciales en tareas específicas. ¡Vamos a descubrirlos!
Ventajas y desventajas
Antes de lanzarnos a instalar nuestro propio LLM, es justo poner las cartas sobre la mesa. Como todo en la vida, optar por el código abierto tiene sus luces y sus sombras.
Las ventajas
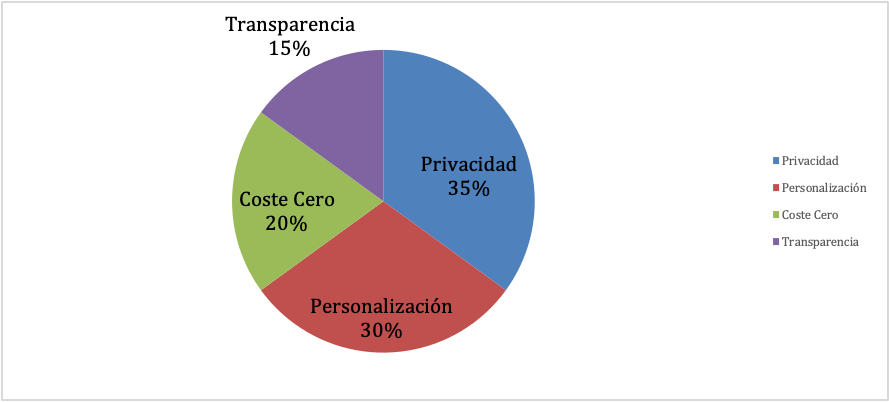
- Privacidad y control total: Al ejecutar el modelo en tu propio hardware, tus datos son solo tuyos. Esto es crucial para manejar información sensible, ya sea personal o empresarial. Como señalan los expertos, la ejecución local garantiza la seguridad de tus datos.
- Personalización extrema: ¿Necesitas un experto en derecho medieval o un asistente que hable como un pirata? Con el código abierto, puedes «ajustar» (fine-tuning) un modelo base con tus propios datos para especializarlo en cualquier tarea o dotarlo de una personalidad única.
- Cero costes de licencia: Olvídate de las suscripciones mensuales. Los modelos de código abierto son gratuitos. Tu única inversión es el hardware y la electricidad para hacerlo funcionar.
- Transparencia e innovación: Al tener acceso al código y a los datos de entrenamiento, la comunidad puede identificar y mitigar sesgos, mejorar la seguridad y construir sobre el trabajo de otros, acelerando la innovación. Esta transparencia genera más confianza que los modelos de «caja negra«.
Los desafíos a considerar
- Requisitos de hardware exigentes: No nos engañemos, estos modelos son bestias computacionales. Necesitarás una buena cantidad de memoria RAM y, sobre todo, una tarjeta gráfica (GPU) con mucha memoria de vídeo (VRAM). Más adelante detallaremos esto.
- Mantenimiento y complejidad: Tú eres el responsable de la instalación, configuración y actualización. Aunque herramientas como Ollama o LM Studio lo han simplificado enormemente, sigue requiriendo un mínimo de esfuerzo técnico.
- Responsabilidad de seguridad: Si bien tus datos están seguros en tu máquina, la responsabilidad de proteger ese sistema recae sobre ti. Debes asegurarte de seguir buenas prácticas de seguridad.
Los 10 titanes del Código Abierto
El año 2026 ha sido testigo de una explosión de modelos de código abierto increíblemente potentes. La competencia es feroz y cada uno brilla en un área distinta. Basándonos en una comparativa exhaustiva de benchmarks, capacidades y popularidad en la comunidad, aquí tienes a los 10 gigantes que están definiendo el futuro de la IA abierta.
1. Qwen3-235B-Instruct-2507
Desarrollado por Alibaba, Qwen3-235B es una bestia. Aunque tiene 235 mil millones de parámetros, utiliza una arquitectura de «Mezcla de Expertos» (MoE) que solo activa 22 mil millones en cada momento, haciéndolo sorprendentemente eficiente. Su última versión, Instruct-2507, es un modelo «no pensante» optimizado para dar respuestas rápidas y precisas.
El políglota de contexto infinito
- Puntos fuertes: Rendimiento excepcional en matemáticas, código y razonamiento lógico. Es multilingüe, con soporte para más de 100 idiomas.
- Característica estrella: Su ventana de contexto nativa es de 262K tokens, pero puede extenderse hasta ¡más de 1 millón de tokens! Esto le permite analizar documentos o bases de código enormes de una sola vez.
- Ideal para: Investigadores, empresas globales y cualquiera que necesite procesar y razonar sobre cantidades masivas de información en varios idiomas.
2. DeepSeek-V3.2-Exp
La familia DeepSeek se ha ganado una reputación por su increíble capacidad de razonamiento. La versión V3.2-Exp introduce una innovación clave: DeepSeek Sparse Attention (DSA). Esta técnica permite al modelo centrarse solo en las partes más relevantes del contexto, reduciendo drásticamente el coste computacional sin sacrificar la calidad.
Eficiencia extrema para contextos largos
- Puntos Fuertes: Mantiene el rendimiento de versiones anteriores pero con un coste de API hasta 10 veces menor en tareas de contexto largo.
- Característica Estrella: Su eficiencia lo convierte en la opción más económica para analizar múltiples documentos o mantener conversaciones muy largas.
- Ideal para: Aplicaciones que dependen de contextos extensos (RAG avanzado, análisis de documentos legales, etc.) y necesitan controlar los costes.
3. Kimi-K2-Instruct-0905
Kimi K2, de Moonshot AI, es un modelo colosal con 1 billón de parámetros totales (32 mil millones activos). Su versión Instruct-0905 está diseñada con un objetivo claro: ser el mejor compañero de programación.
El asistente de código agéntico
- Puntos Fuertes: Inteligencia «agéntica» para código. No solo escribe código, sino que puede interactuar con herramientas, ejecutarlo y depurarlo de forma autónoma.
- Característica Estrella: Una ventana de contexto de 256K tokens y un rendimiento sobresaliente en benchmarks de desarrollo de software como SWE-Bench, donde compite cara a cara con modelos cerrados de élite.
- Ideal para: Desarrolladores que buscan un copiloto de IA capaz de realizar tareas complejas de ingeniería de software de principio a fin.
4. DeepSeek-R1-0528
Si lo tuyo son las matemáticas, la lógica y el razonamiento profundo, DeepSeek-R1 es tu modelo. Esta versión, mejorada con aprendizaje por refuerzo, ha sido entrenada para pensar de forma más analítica y profunda, lo que se refleja en sus impresionantes resultados en pruebas de matemáticas y lógica.
El maestro del razonamiento complejo
- Puntos Fuertes: Rendimiento a nivel de los mejores modelos propietarios en matemáticas (AIME 2025), programación y lógica general.
- Característica Estrella: Su capacidad para generar cadenas de pensamiento más largas y complejas, lo que le permite resolver problemas que otros modelos no pueden.
- Ideal para: Investigación científica, análisis financiero y cualquier tarea que requiera un razonamiento deductivo impecable.
5. Llama-3.3-Nemotron-Super-49B
NVIDIA ha tomado el ya excelente Llama-3.3 de Meta y lo ha optimizado para crear Nemotron-Super-49B. Este modelo de 49 mil millones de parámetros está diseñado para ser un todoterreno, equilibrando razonamiento, uso de herramientas y eficiencia.
El equilibrio perfecto de NVIDIA
- Puntos Fuertes: Optimizado para flujos de trabajo con agentes de IA, RAG (Generación Aumentada por Recuperación) y llamadas a funciones.
- Característica Estrella: Ofrece un rendimiento muy sólido en un tamaño relativamente manejable, con una ventana de contexto de 128K tokens y un excelente soporte por parte del ecosistema de NVIDIA.
- Ideal para: Desarrolladores que construyen chatbots y agentes de IA complejos que necesitan interactuar con APIs y bases de datos externas.
6. gpt-oss-120B
OpenAI sorprendió a todos con el lanzamiento de gpt-oss-120B, su primer modelo de pesos abiertos de gran escala. Con 117 mil millones de parámetros (5.1B activos), este modelo MoE ofrece un rendimiento cercano a GPT-4o-mini y está diseñado para ser eficiente.
La potencia de OpenAI, ahora abierta
- Puntos Fuertes: Excelente en razonamiento, código y tareas generales. Ofrece profundidad de razonamiento configurable para equilibrar calidad y latencia.
- Característica Estrella: Gracias a la cuantificación MXFP4, puede ejecutarse en una única GPU de 80 GB, un hito para un modelo de su tamaño.
- Ideal para: Empresas y desarrolladores que buscan la calidad de OpenAI en un formato abierto y desplegable localmente.
7. Apriel-1.5-15B-Thinker
ServiceNow ha logrado una proeza de eficiencia con Apriel-1.5-15B-Thinker. Este modelo de solo 15 mil millones de parámetros no solo razona con texto, sino también con imágenes, y lo hace con un rendimiento que compite con modelos mucho más grandes.
Inteligencia multimodal en una sola GPU
- Puntos Fuertes: Capacidades multimodales (texto e imagen) con un consumo de recursos muy bajo.
- Característica Estrella: Está diseñado para funcionar en una única GPU de gama de consumidor, lo que lo hace increíblemente accesible para la experimentación y el despliegue en entornos empresariales.
- Ideal para: Desarrolladores que quieren construir aplicaciones que entiendan tanto texto como imágenes sin necesidad de un centro de datos.
8. Mistral-Small-3.2-24B
Mistral AI continúa su legado de crear modelos eficientes y de alta calidad. Mistral-Small-3.2 es un modelo de 24 mil millones de parámetros que destaca por su fiabilidad y su capacidad para seguir instrucciones complejas.
El compacto y fiable
- Puntos Fuertes: Ha mejorado significativamente en el seguimiento de instrucciones y ha reducido a la mitad los errores de repetición en comparación con su predecesor.
- Característica Estrella: Ofrece un gran equilibrio entre tamaño, velocidad y calidad, siendo una opción muy popular y accesible en múltiples plataformas.
- Ideal para: Tareas de asistente general, chatbots y aplicaciones donde la fiabilidad y la precisión en las respuestas son clave.
9. GLM 4.6
Desarrollado por Zhipu AI, GLM 4.6 es un modelo muy competente que ha mejorado sus ya sólidas capacidades de razonamiento y codificación. Es conocido por su estabilidad y su buen rendimiento en una amplia gama de tareas.
El todoterreno para razonamiento y código
- Puntos Fuertes: Razonamiento sólido, flujos de trabajo agénticos y una ventana de contexto ampliada a 200K tokens.
- Característica Estrella: Es un modelo muy equilibrado que funciona bien en casi todo, lo que lo convierte en una excelente opción de propósito general.
- Ideal para: Desarrolladores que necesitan un modelo versátil para construir aplicaciones que combinen chat, código y razonamiento.
10. MiniMax-M1-80k
MiniMax-M1 es otro gigante del contexto largo. Con una arquitectura MoE híbrida de 456 mil millones de parámetros, está diseñado para ser extremadamente eficiente al procesar secuencias largas. Su versión M1-80k es una de las más populares.
El devorador de documentos
- Puntos Fuertes: Soporte nativo para un contexto de 1 millón de tokens, superando a casi todos sus competidores.
- Característica Estrella: Su arquitectura de atención híbrida le permite procesar estos contextos masivos con una eficiencia computacional un 75% mayor que otros modelos.
- Ideal para: Investigación profunda, análisis de bases de código a escala de repositorio y cualquier tarea que requiera «leer» y comprender múltiples libros a la vez.
Comparativa de rendimiento
Los números no mienten. Para entender mejor dónde destaca cada modelo, hemos recopilado sus puntuaciones en tres áreas críticas:
- Razonamiento y Lógica (medido con el benchmark AIME 2025)
- Programación (con SWE-Bench)
- Capacidad General (con MMLU-Pro)
Estas pruebas miden desde la resolución de problemas matemáticos complejos hasta la capacidad de arreglar errores en código real y el conocimiento general del mundo.
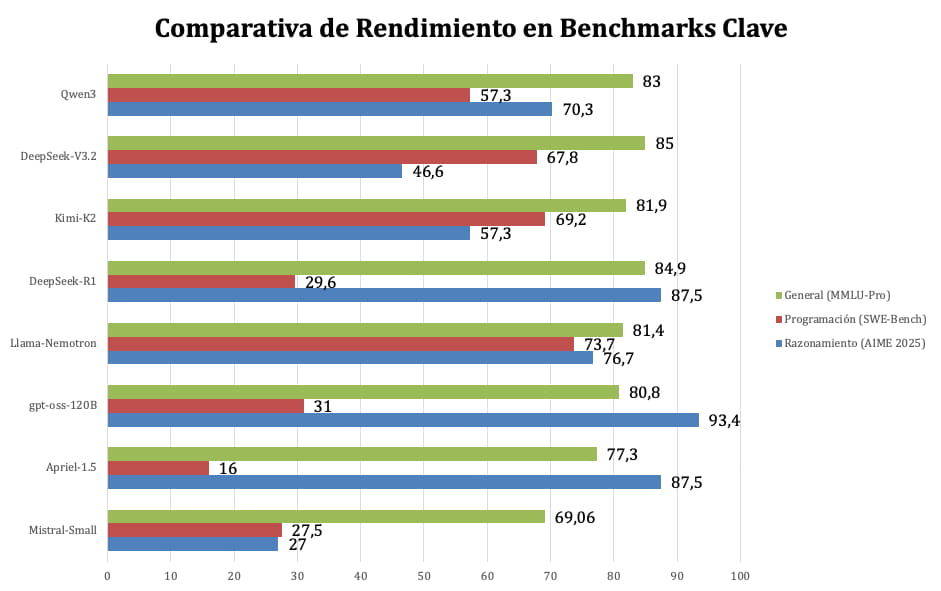
Fuente: Datos extraídos de benchmarks públicos.
Como muestra el gráfico, no hay un único ganador absoluto. DeepSeek-R1 y Qwen3 demuestran una capacidad de razonamiento matemático sobresaliente. En programación, Kimi-K2 se posiciona como un líder indiscutible, diseñado específicamente para tareas de desarrollo de software. Por otro lado, modelos como Qwen3 y DeepSeek-V3.2 muestran un conocimiento general muy robusto, lo que los hace excelentes para tareas de propósito general. Modelos más pequeños como Apriel y Mistral-Small ofrecen un rendimiento muy respetable para su tamaño, destacando por su eficiencia.
Cómo ejecutar un LLM en tu ordenador
¿Te animas a probar uno de estos modelos en casa? ¡Genial! La comunidad ha creado herramientas fantásticas que hacen que el proceso sea más fácil que nunca. Aquí te explicamos lo que necesitas.
La Clave está en la VRAM
El componente crítico para ejecutar un LLM localmente es la memoria de vídeo (VRAM) de tu tarjeta gráfica (GPU). Cuanto más grande es el modelo, más VRAM necesita. La segunda clave es el ancho de banda de la memoria, que determina la velocidad a la que el modelo puede leer y escribir datos, afectando directamente a la velocidad de generación de texto (tokens por segundo).
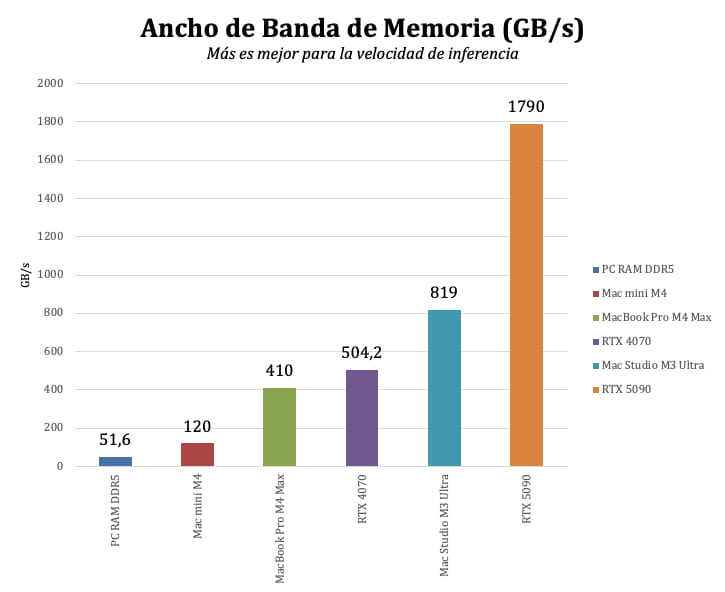
Fuente: Xataka y Introl Hardware Guide 2025.
Aquí tienes una guía aproximada de la VRAM que necesitas según el tamaño del modelo (sin cuantizar, en precisión FP16):
- Modelos pequeños (7B – 15B): Necesitarás al menos 16 GB de VRAM. Una NVIDIA RTX 3080, 4070 o superior es una buena opción.
- Modelos medianos (30B – 70B): Aquí entramos en territorio serio. Se recomiendan 24 GB a 48 GB de VRAM. La NVIDIA RTX 4090 (24 GB) es una opción popular, aunque para los modelos más grandes de este rango podrías necesitar dos o una GPU profesional como la RTX 5090 (32 GB).
- Modelos grandes (120B+): Estos son para entusiastas con hardware de nivel de centro de datos. Requieren 80 GB de VRAM o más, lo que generalmente implica múltiples GPUs de alta gama (ej. 2x H100 80GB) o sistemas con memoria unificada como el Mac Studio con chip M3/M4 Ultra (hasta 512 GB).
¿Qué es la cuantización? Es una técnica para reducir el tamaño de un modelo (y su consumo de VRAM) comprimiendo sus pesos. Formatos como GGUF o AWQ permiten ejecutar modelos grandes en hardware más modesto, con una pérdida de calidad a menudo imperceptible. Por ejemplo, un modelo de 70B que requiere ~140 GB de VRAM puede ejecutarse en una GPU de 24 GB usando cuantización de 4 bits.
Software y herramientas
Olvídate de compilar código y lidiar con dependencias complejas. Hoy en día, existen aplicaciones «todo en uno» que hacen que instalar y usar un LLM sea tan fácil como instalar cualquier otro programa.
- LM Studio: Probablemente la opción más popular para empezar. Tiene una interfaz gráfica muy intuitiva. Simplemente buscas el modelo que quieres en su catálogo (que se conecta a Hugging Face), eliges la versión cuantizada que se ajuste a tu hardware y le das a descargar. ¡Listo! Ya puedes chatear con él.
- Jan.ai: Una alternativa de código abierto a LM Studio, centrada en la privacidad y con una interfaz muy pulida y similar a ChatGPT. Permite importar modelos que ya tengas descargados y también se integra con APIs externas.
- Ollama: Para los que se sienten cómodos con la línea de comandos. Es extremadamente ligero y eficiente. Una vez instalado, solo tienes que escribir `ollama run nombredelmodelo` en tu terminal para descargar y empezar a usar un LLM.
- vLLM: Si eres un desarrollador y quieres construir una aplicación sobre un LLM local, vLLM es el motor de inferencia de referencia. Está optimizado para un alto rendimiento y baja latencia, ideal para entornos de producción.
Qué modelo elegir según tus necesidades
Con tantos modelos increíbles, la elección puede ser abrumadora. Aquí tienes una guía rápida para ayudarte a decidir cuál se adapta mejor a ti, basada en casos de uso comunes.
Fuente: Análisis basado en los puntos fuertes de cada modelo.
- Para programación y desarrollo de software:
- Elección Top: Kimi-K2-Instruct-0905. Su enfoque agéntico y su rendimiento en benchmarks de código lo hacen inigualable.
- Alternativa: DeepSeek-R1-0528. Su potente razonamiento también se traduce en una excelente capacidad para resolver problemas de programación complejos.
- Para investigación y análisis de documentos:
- Elección Top: MiniMax-M1-80k o Qwen3-235B. Su capacidad para manejar contextos de hasta 1 millón de tokens es revolucionaria para analizar grandes volúmenes de texto.
- Alternativa Económica: DeepSeek-V3.2-Exp. Ofrece un excelente rendimiento en contexto largo a una fracción del coste computacional.
- Para tareas de razonamiento, lógica y matemáticas:
- Elección Top: DeepSeek-R1-0528. Está específicamente entrenado para el pensamiento analítico profundo.
- Alternativa: gpt-oss-120B. Ofrece un razonamiento configurable y de alta calidad, con el sello de OpenAI.
- Para uso general y chatbots:
- Elección Top: Llama-3.3-Nemotron-Super-49B. Es un modelo muy equilibrado, versátil y optimizado.
- Alternativa Ligera: Mistral-Small-3.2-24B. Es fiable, rápido y excelente para seguir instrucciones, ideal para un asistente personal.
- Para experimentación multimodal (texto + imagen):
- Elección Única: Apriel-1.5-15B-Thinker. Es el único de la lista con capacidades multimodales nativas y la ventaja de poder ejecutarse en hardware de consumo.
El futuro es abierto y personalizable
El panorama de los LLM de código abierto en 2026 es más emocionante que nunca. Hemos pasado de modelos experimentales a auténticas potencias que no solo rivalizan, sino que a menudo superan a las alternativas comerciales en áreas clave como la programación, el razonamiento y el manejo de contextos largos. La verdadera revolución no está solo en su rendimiento, sino en la libertad que ofrecen.
La capacidad de ejecutar una IA de vanguardia en tu propio ordenador, con control total sobre tus datos y la posibilidad de adaptarla a tus necesidades exactas, es un cambio de paradigma. Ya no somos meros consumidores de IA; nos estamos convirtiendo en creadores y personalizadores. Si bien los requisitos de hardware siguen siendo un factor a tener en cuenta, la rápida evolución de las técnicas de cuantización y la aparición de modelos más eficientes como Apriel o Mistral están haciendo que la IA local sea accesible para un público cada vez más amplio.
Así que, si tienes la curiosidad y el hardware adecuado, no hay mejor momento para sumergirte en el mundo de los LLM de código abierto. Elige un modelo, descarga una herramienta como LM Studio o Ollama, y empieza a explorar. El futuro de la inteligencia artificial no es algo que simplemente observamos; es algo que podemos construir, moldear y poseer.