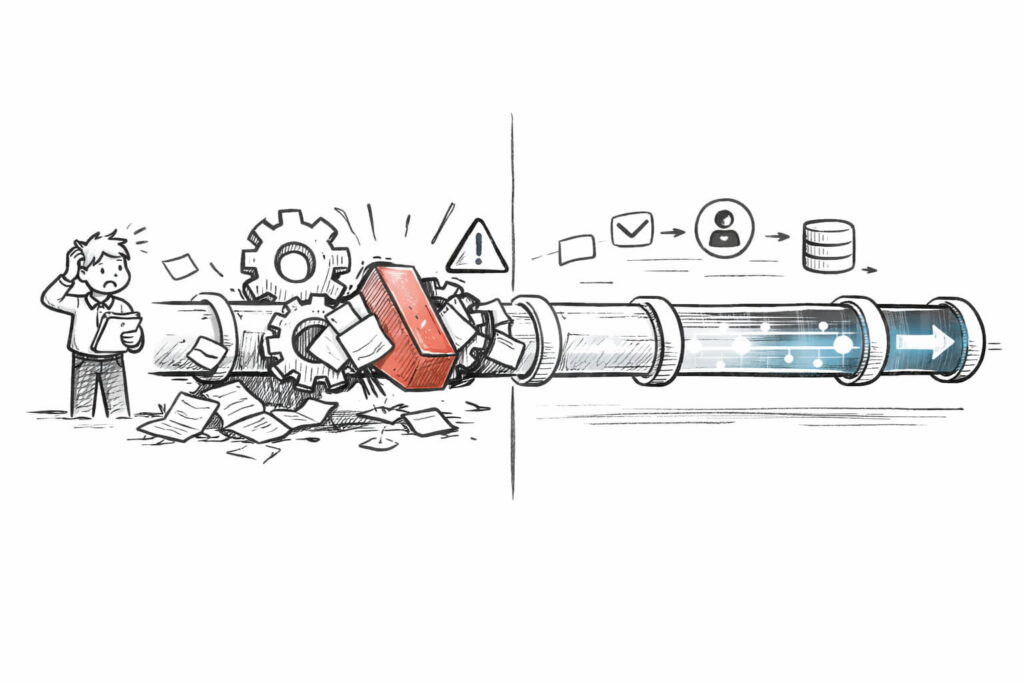
Uno de los momentos más peligrosos para un líder tecnológico es el «éxito repentino«. Imagina que has diseñado un flujo con IA que gestiona las reclamaciones de los clientes y funciona de maravilla para 10 correos al día. Pero, de repente, lanzas una campaña, el volumen sube a 2,000 correos diarios y el sistema colapsa: las APIs se bloquean, los datos se mezclan y los clientes reciben respuestas vacías o erróneas.
Pasar de un prototipo (un modelo de prueba) a una solución escalable requiere dejar de pensar en «scripts» (instrucciones simples) y empezar a pensar en arquitectura. En este artículo, desglosaremos los pilares técnicos para construir una automatización que no solo sea inteligente, sino industrialmente robusta.
Arquitectura modular: El poder de los microservicios
En lugar de construir una automatización gigante que haga todo (un «monolito«), la escalabilidad exige modularidad.
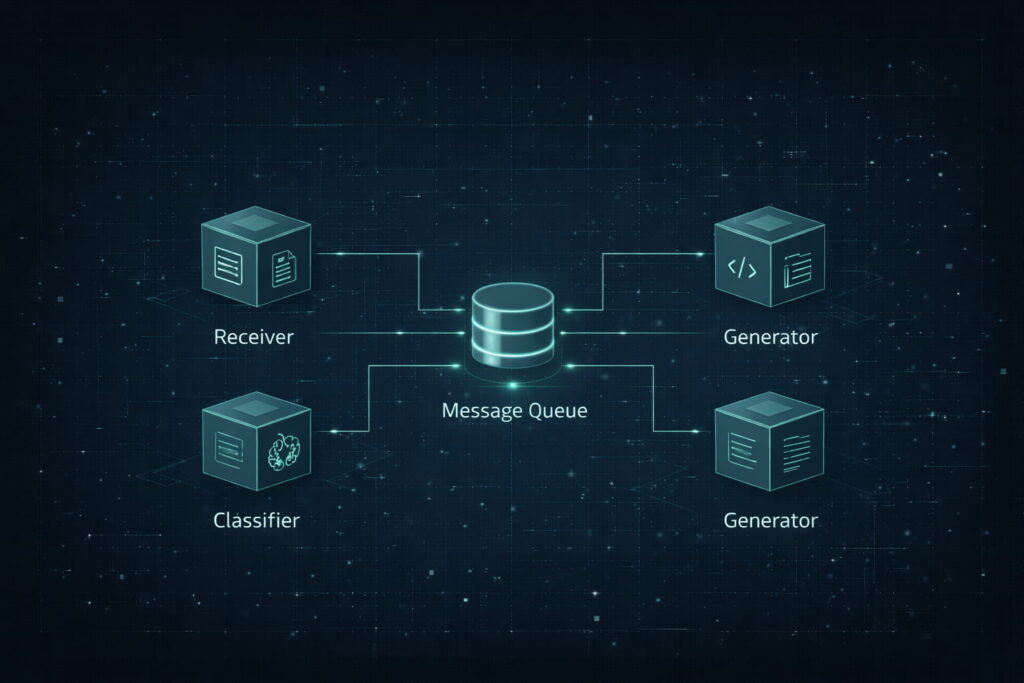
Técnicamente, esto se logra dividiendo el proceso en piezas independientes llamadas Microservicios. Imagina que tu flujo de trabajo es un restaurante: en lugar de tener a una sola persona que toma la orden, cocina, sirve y lava los platos (lo cual colapsaría si llegan 50 clientes a la vez), divides las tareas en estaciones independientes.
- Módulo A (El Receptor): Solo se encarga de extraer el texto de los correos entrantes.
- Módulo B (El Analista): Solo clasifica la intención (¿es queja, es compra o es spam?).
- Módulo C (El Redactor): Solo genera el borrador de respuesta.
¿Por qué esto escala mejor?
Si el módulo de redacción falla porque la API de la IA está caída, el sistema no muere. Los correos siguen entrando y siendo clasificados por los otros módulos. Cuando la IA vuelve a estar en línea, el Módulo C simplemente retoma el trabajo acumulado. Esta independencia permite que cada pieza crezca o se repare sin detener toda la maquinaria.
Gestión de colas y mensajería: El «Buffer» de seguridad
En el mundo de la IA, trabajamos con servicios externos que tienen límites. Si intentas enviar 500 peticiones en un solo segundo a un modelo como GPT-4, el sistema te responderá con un error de Rate Limit Exceeded (Límite de velocidad excedido). Es como intentar meter a 500 personas a la vez por una puerta giratoria: nadie entra.
Para solucionar esto, los flujos escalables utilizan Colas de Mensajes (Message Queues).
Explicación técnica: Una cola es un sistema intermedio (como un «almacén» temporal) que recibe todas las peticiones y las entrega a la IA una por una, a la velocidad exacta que la IA puede procesar.
- Si llegan 1,000 correos en un minuto, la cola los guarda.
- El procesador de IA va sacando correos de la cola de forma ordenada.
- Esto garantiza que ningún dato se pierda y que el sistema nunca se bloquee por saturación. Es la diferencia entre un atasco de tráfico y una fila de peaje bien organizada.
Idempotencia: El seguro contra la duplicidad
Este es un tecnicismo crítico pero poco conocido: la Idempotencia.
Imagina que tu sistema envía una factura automáticamente. Hay un fallo de red justo en el milisegundo en que se envía, y el sistema, al no recibir confirmación, lo intenta de nuevo. Si tu flujo no es idempotente, el cliente recibirá dos facturas (y dos cargos).
Un proceso idempotente es aquel que, sin importar cuántas veces se ejecute con la misma información, el resultado final siempre es el mismo. Técnicamente, esto se logra asignando un «Identificador Único» a cada tarea. El sistema revisa: «¿Ya procesé el pedido #456?». Si la respuesta es sí, ignora la petición repetida. Sin idempotencia, escalar una automatización es invitar al caos de los datos duplicados.
Gestión de errores (Error Handling) y «Fallar con Elegancia«
En un sistema pequeño, si algo falla, lo arreglas a mano. En un sistema que procesa miles de tareas, el error debe estar previsto en el diseño. Esto se conoce como Error Handling.
Existen dos estrategias clave para que el sistema «falle con elegancia«:
- Dead Letter Queues (Colas de cartas muertas): Si una tarea falla tres veces (por ejemplo, porque el PDF adjunto está corrupto), el sistema no se detiene. Envía esa tarea específica a una «cola de errores» para que un humano la revise más tarde, mientras el flujo principal sigue procesando el resto de tareas con normalidad.
- Retries con Exponential Backoff (Reintentos con espera exponencial): Si una API falla, no es inteligente reintentar inmediatamente cada segundo (podrías saturar más el servicio). El sistema espera 1 segundo, luego 2, luego 4, luego 8… Esto da tiempo a que los servicios técnicos se recuperen sin que tú pierdas el turno en la cola.
El concepto de «Observabilidad»: Ver dentro de la Caja Negra
Muchos flujos de IA se convierten en «Cajas Negras«: entra información y sale un resultado, pero nadie sabe qué pasa dentro. Cuando escalas, necesitas Observabilidad.
No basta con saber que el sistema «está encendido«. Necesitas métricas técnicas en tiempo real:
- Latencia: ¿Cuánto tarda la IA en responder hoy comparado con ayer?
- Tasa de Error: ¿Qué porcentaje de tareas están terminando en la «cola de errores»?
- Costo de Inferencia: ¿Cuánto dinero estamos gastando en tokens por cada hora de operación?
Técnicamente, esto se implementa mediante Logs (registros de actividad) detallados. Si un cliente se queja de una respuesta errónea, la observabilidad te permite rastrear exactamente qué versión de la IA respondió, qué datos recibió y por qué decidió lo que decidió.
De la agilidad a la resiliencia
Construir un flujo que funcione es fácil; construir uno que soporte el peso de una empresa entera es ingeniería. La escalabilidad no se trata de comprar servidores más grandes, sino de diseñar un sistema elástico y resiliente.
Al implementar arquitectura modular, colas de mensajes, procesos idempotentes y una sólida gestión de errores, estás transformando la IA de un simple «asistente» en una infraestructura industrial. Esta base es la que permitirá que tu empresa crezca sin límites, sabiendo que la tecnología no solo seguirá el ritmo, sino que protegerá la integridad de cada operación.